


A World Without Google
Decentralised discoverability: is it possible?

A friend of mine commented on a previous article, WebFree: You Are the Platform, and raised a really interesting point:
Discoverability seems to still only be solved via centralised platforms.
This was in response to a discussion about the decentralised nature of NFTs.
When I mint a new NFT it quickly becomes visible on both of these marketplaces, not through any action I took, other than simply minting a new NFT, but because there’s an open standard governing NFTs and any marketplace that wants to list NFTs must conform to the standard.
My friend pointed out that although the NFTs themselves are decentralised you still have to use centralised marketplaces, like LooksRare and OpenSea, to discover them.
This got me thinking. So of course I had to write an article about it.
What is discoverability?
Let’s define some things first.
Discoverability is the ease with which a user can find relevant content.
On the internet in general this is facilitated by search engines, like Google.
Discoverability of most web pages is governed by Google’s search algorithm. In short, Google decides how web pages get ranked and displayed to users.
We can also think about this in terms of music.
How easy is it to find Taylor Swift’s latest album on your favourite music platform?
That’s her discoverability.
How easy is it to find new music that you haven’t heard before but you like once you hear it?
This is another aspect of discoverability.
I use Spotify because I’m obsessed with music and I want to discover new music that I enjoy.
So Spotify serves me by providing new music that they think I’ll enjoy based on my listening history and likes and probably a bunch of other stuff.
In general, we can boil discoverability down to two things:
Finding the things you’re looking for
Finding things you’re not looking for but are relevant to you in some way
It’s about providing the things that I’m actively looking for and enhancing my experience by providing related content.
Some more examples of centralised platforms that provide a discovery service:
Shopify - App Store
Apple - App Store
Instagram - Feed, Discover, Search, Reels, Shopping
Facebook - Feed, Marketplace, Watch
TikTok - Home, Discover
Airbnb - Places to stay, Experiences, Online Experiences
YouTube - Home, Explore, Shorts, Subscriptions
All these platforms have “search” in one form or another.
So discoverability is a big thing.
And why is it a big thing?
Because the internet is huge.
The internet is a network of interconnected servers and clients.
Let’s imagine none of these platforms and aggregators exist.
Imagine a world without Google.
If you’re in Toronto and want to learn how to cook sous vide steak, and all the sous vide steak cooking videos are on a server in Tel Aviv, how would you find them?
You’d need to navigate to the exact web domain.
But if you didn’t know they were there and you didn’t know the domain how would you find them?
Without Google it becomes impossibly hard to discover sous vide steak cooking videos.
Like driving without a map or street signs.
Feels like the Dark Ages to me.
The funny thing is, most of the internet is decentralised.
Anyone can create a web page, buy a domain name, and host their own site.
No centralised party controls this.
BUT nobody will visit your website if they don’t know it exists.
So even though the supply of information on the internet is decentralised, the demand has become concentrated via centralised aggregators like Google.
Ben Thompson has written a great deal about this in Stratechery. I want to highlight this section in particular from OpenSea, Web3, and Aggregation Theory:
In fact, what gives Aggregators their power is not their control of supply: they are not the only way to find websites, or to post your opinions online; rather, it is their control of demand. People are used to Google, or it is the default, so sites and advertisers don’t want to spend their time and money on alternatives; people want other people to see what they have to say, so they don’t want to risk writing a blog that no one reads, or spending time on a social network that because it lacks the network has no sense of social.
Google is a centralised aggregator, helping you to discover decentralised information.
The Tel Aviv sous vide steak videos are not owned by Google and they’re not stored on Google’s servers, but Google helps people all over the world to find these videos when they search for them.
This is why Google has become so powerful. They’re essentially the gatekeepers of the internet because they control demand.
Their algorithms decide what information gets returned for each search query and there is no alternative besides other search engines.
And even other search engines don’t offer much competition, as shown here:

Google held over 80% of desktop/laptop search engine market share for the last 12 months. Get this: it’s even higher for mobile search engine usage, hovering around 95%.
This is important because it illustrates exactly how much power Google has over discoverability.
When you consider that about 93% of all web traffic is via a search engine, this essentially means that a small group of people in Silicon Valley control what the majority of internet users discover.
This is astounding.
How can a single company have so much power?
Why are they so popular?
I think that’s a bigger topic for another day.
What do I have to say about Google and centralisation?
Well we’re supposed to be talking about NFTs and how they’re decentralised but the discovery platforms are centralised.
We’ll get there.
Finding a sous vide steak video in a haystack
In order to understand if decentralised discovery is possible, we first need to understand the current, centralised process. So let’s break down the process of how we’d find our sous vide steak videos today.
It’s likely we’d go to Google and search for something like, “video about how to make sous vide steak”.
There’s a lot to unpack in that first bit when we “go to Google”.
When you visit Google.com, Google.ca, or whichever regional version you use, you see the same classic landing page.

I’m sure y’all are familiar with that.
But what is this page? What is it made of? Where does it come from?
Hold onto your butts, we're going to get technical.

If I open Chrome DevTools and inspect what happens when I navigate to Google.ca I see a few things:
I get redirected from google.ca to www.google.ca

After the redirect my browser receives some HTML code that represents the visual elements you can see on screen, including the search bar and buttons
The HTML also includes come JavaScript code that requests other scripts and images, and provides the functionality to create a search query

So how does this stuff get to your browser?
When I type google.ca in my browser’s URL bar and hit enter, my browser needs to find the correct Internet Protocol (IP) address for the server that holds Google’s code.
Google’s homepage HTML is stored on a bunch of servers around the world and my laptop needs to find the specific IP address of one of these servers so it can request the homepage for me.
Here’s the IP address I get:
142.250.31.94
That means nothing to me and it’s not easy to remember.
No way I’m going to remember the IP address of my favourite websites.
Luckily I don’t have to. I can remember the domain name instead.
Google.ca is a domain name which can be assigned and reassigned to an IP address many times over.
Domain names exist because they’re memorable references tied to IP addresses.
So how does my browser tie a domain name to an IP address?
Using the Domain Name System (DNS).
When we type google.ca in a web browser and hit enter a lot of stuff happens before we get to see the landing page.
The first thing that happens is the browser tries to find the IP address associated with google.ca and it does this via a DNS lookup.
The full details of how this works is beyond the scope of this article but Kyle Lee wrote a great post on the AWS blog about it, here’s an excerpt about DNS lookups:
Because DNS is complex and has to be blazingly fast, DNS data is cached at different layers between your browser and at various places across the Internet. Your browser checks its own cache, the operating system cache, a local network cache at your router, and a DNS server cache on your corporate network or at your internet service provider (ISP). If the browser cannot find the IP address at any of those cache layers, the DNS server on your corporate network or at your ISP does a recursive DNS lookup. A recursive DNS lookup asks multiple DNS servers around the Internet, which in turn ask more DNS servers for the DNS record until it is found.
Once the browser gets the DNS record with the IP address, it’s time for it to find the server on the Internet and establish a connection.
Here’s a diagram showing the simplified version of how this works, using Google.ca as an example:

Okay so all of that happened just for us to arrive at the Google landing page.
Now we type “video about how to make sous vide steak” into the search bar and hit enter.
And voila, almost immediately we’re presented with a list of videos about sous vide steak.

Well how does that bit work?
The moment we hit enter on the search bar the code on Google’s landing page created a new URL for us to navigate to:
https://www.google.ca/search?q=video+about+how+to+make+sous+vide+steak&source=hp&ei=-TEr… (truncated for brevity)
Yours may or may not be exactly the same as this but the key part is the search query which I highlighted above.
This is called a query string.
When our browser navigates to this URL it sends a request to Google’s server, specifically on the search path with the query string highlighted above (and a bunch of other query strings that aren’t human-readable and probably relate to analytics or tracking or something).
Google’s server receives this request and does whatever it does to find what it deems the most relevant results for my search query, “video about how to make sous vide steak”.
The server returns more HTML and JavaScript code that makes up the search result page and the specific search results it found for us.
On the screen we see the search results:
Which is essentially a list of web URLs with some extra data like web
page description, video preview images, page title etc.
But really it’s no more than a list of URLs.
The other data is only given to help us choose which page we want to visit.
So let’s check out the first video about sous vide steak, hit the link.
Now we’re triggering another DNS lookup because Google only gave us the URL, not the IP address of the server that holds the code for the specific page about sous vide steak.
The URL is https://www.youtube[dot]com/watch?v=1_TRxJ802UY (I added [dot] because Substack’s blog editor kept embedding the actual video).
And now we go through this process again:

Except we’re not looking for "Google.ca”, we’re looking for “YouTube.com”.
And finally we get the YouTube page:

A loooooot of stuff happened in the background for us to get here.
The question is, “Can the whole process be decentralised?”
Is decentralised discovery possible?
Okay, so we went through the current process of finding videos about sous vide steak.

And we used various decentralised and centralised services to get there.
The centralised parts are:
Google
Search page
Results page
Search server and algorithm
Yeah, YouTube is also centralised but we didn’t use YouTube to discover the video, it was just one of the results that Google provided.
So the Search page.
Could this be decentralised?
What does it mean to be “decentralised”?
Remember how we retrieved the search page code, we typed in Google.ca, found the IP address via a DNS lookup, and then made a request to the IP address in order to get the code.
To be decentralised in this case it’d mean that the search page code would have to be distributed across multiple servers and those servers not be controlled by a single entity.
But how would the DNS lookup know which server to return?
If the code is on multiple servers then there are multiple IP addresses and a DNS lookup only returns a single IP address.
Well we’d need a system like InterPlanetary File System (IPFS), described as:
A peer-to-peer hypermedia protocol designed to preserve and grow humanity's knowledge by making the web upgradeable, resilient, and more open.
It’s essentially a network of servers that store data in a distributed and decentralised way.
Anybody can run an IPFS node (i.e. server) and when doing so they choose which data to pin to the node (i.e. store on the server).
And in doing so they make that data available for themselves and the rest of the network.
It’s even possible to store entire websites on IPFS.
It is just data storage after all, just distributed and decentralised data storage.
No single entity (corporate or otherwise) controls the network.
Nobody can shut it down.
So we could host Google’s search page (or a page with the same functionality) on an IPFS node.
That’s great but who decides what’s on the page and how it works?
The UI could be developed by a group of people, open-sourced, and made available to anyone who wanted to use it.
There could even be multiple UIs. This happens all the time in DeFi.
A group creates an open DeFi protocol, like Uniswap, and anyone can build a UI to interact with it, so a few UIs spring up and users choose the one they like best.
Why not do the same for search?
Create an open protocol that indexes the internet, and allow others to create UIs that interact with it.
As shown in the diagram above, Google’s centralised architecture looks something like this:
(I realise YouTube is owned by Google, but I want to delineate between Google Search services and YouTube)
And I can imagine a decentralised architecture like this:
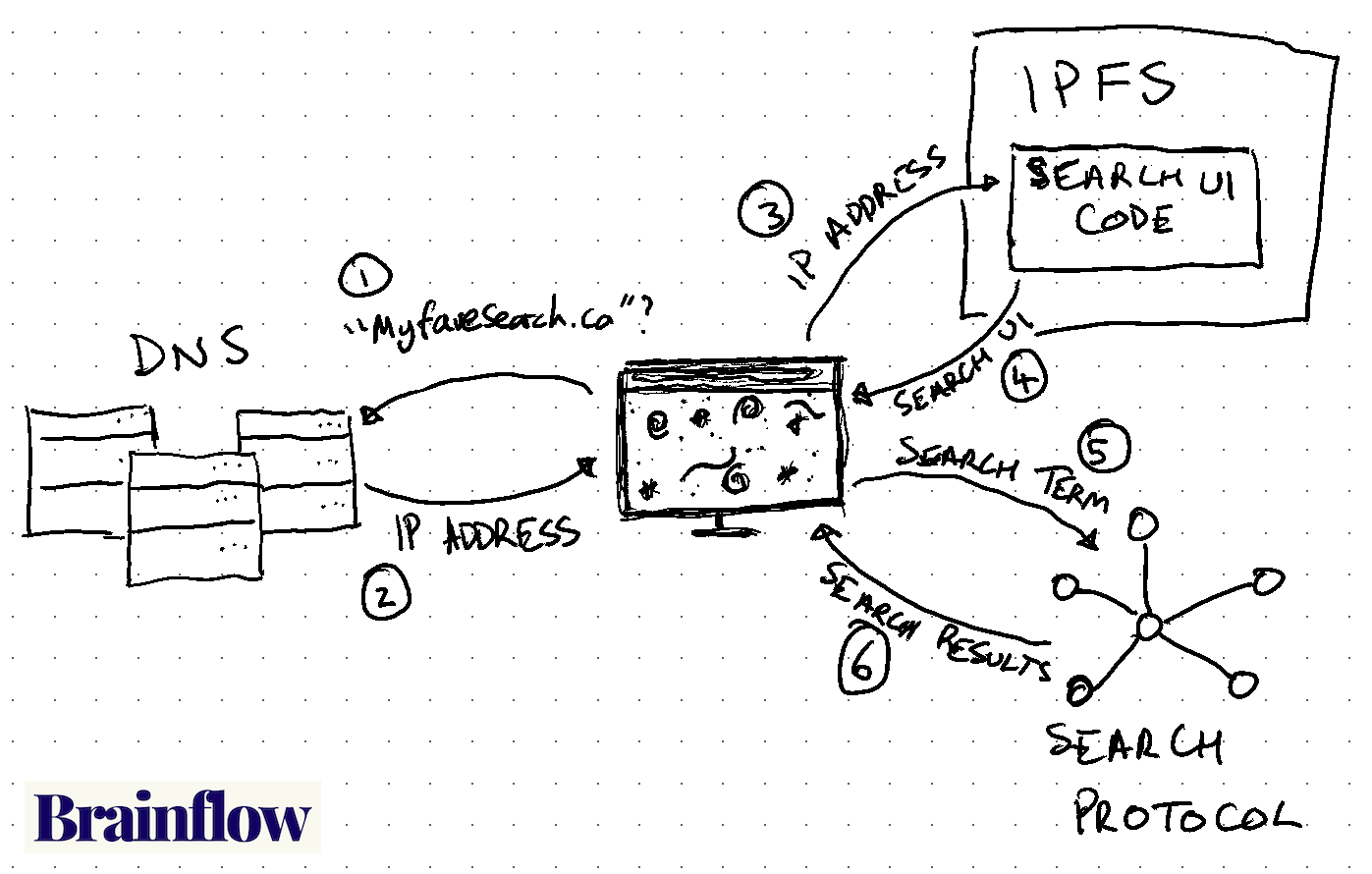
Both diagrams look similar on the surface, just Google has been replaced by IPFS and a Search Protocol.
The key here is in the centralised model we navigate to “google.ca” and in the decentralised model it’s “myfavesearch.ca” but this could be any number of search UIs created by any number of parties.
The Search Protocol replaces Google’s search algorithm and it also decouples the UI from the backend, meaning that any number of UIs can interact with the protocol.
The idea being that the protocol provides search results when given a query, and that people all around the world set up nodes to participate in the protocol and index the internet in a distributed and decentralised way.
It’s possible we get to the same YouTube video about sous vide steak, but it’s also possible we won’t because the Search Protocol algorithm might return different results than Google, even for the same search term.
And that’s important because now the power to change the algorithm is distributed among network participants all over the world instead of a few people in California.
So, yeah, I think decentralised discovery is possible.
If you want to go ahead and build it, let me know. I’ll buy into that all day long.
But, and this is key, it’s pointless if nobody uses it.
In my opinion, this is the biggest hurdle to overcome: How does one retrain internet users to use something other than Google?
In other words, how do we take the demand from Google and distribute it among other, decentralised search UIs?
I’ll leave you with that question for now.
Until next time 👋
Thank you to Agnes Pyrchla, Davey Morse, Stew Fortier, and Tom White for their contributions to and feedback on this article ❤️